Twenty-plus years in enterprise data has taught me that technology problems are rarely technology problems.
They usually masquerade as technology problems for a while. The whole debate stays comfortably technical, until somewhere along the way, somebody asks a deceptively simple question, and the entire conversation changes.
That happened to me during a high-stakes business merger.
At the time, the focus was on integration. Two organizations were becoming one. Company A was acquiring Company B. Systems needed to be consolidated, applications rationalized, platforms aligned, and operating models standardized. It was the kind of transformation that happens every day across large enterprises. The difference was scale and the timeline.
Like most mergers, the initial conversations centered around technology. What would the future-state architecture look like? Which platforms would survive? Which tools would be retired? How quickly could we complete the integration?
Then somebody asked a question that should have been easy to answer.
"Which datasets are we actually migrating?"
The room became noticeably quieter.
Not because the question was hard to understand, but because nobody had ever had to answer it before.
In day-to-day operations, you never decide, dataset by dataset, what deserves to survive. A merger forces exactly that question, across the entire ecosystem, all at once. And in that moment, it was clear that none of us actually knew.
When "Move Everything" Stops Being a Strategy
If you've ever moved houses after living in the same place for twenty years, you know the feeling. At first, the plan sounds simple. Pack everything, load the truck, move into the new place.
Then reality arrives.
You discover boxes in the attic that haven't been opened in a decade. There are things in the garage that nobody remembers buying. Some items are unquestionably valuable. Others should have been discarded years ago. Most fall into a gray area where nobody is entirely sure whether they're important, sentimental, useful, or simply taking up space.
Enterprise data behaves exactly the same way.
The company being acquired operated a sizeable data ecosystem: tens of petabytes across cloud and legacy data platforms, and well over a million datasets spread across raw zones, staging environments, curated layers, analytical marts, and sandboxes accumulated over years of business operations. To complicate matters, there were hundreds of data stewards across the organization and thousands of consumers running millions of queries each day.
Most people hear those numbers and think the challenge was scale. It wasn't. The challenge was deciding what deserved to survive.
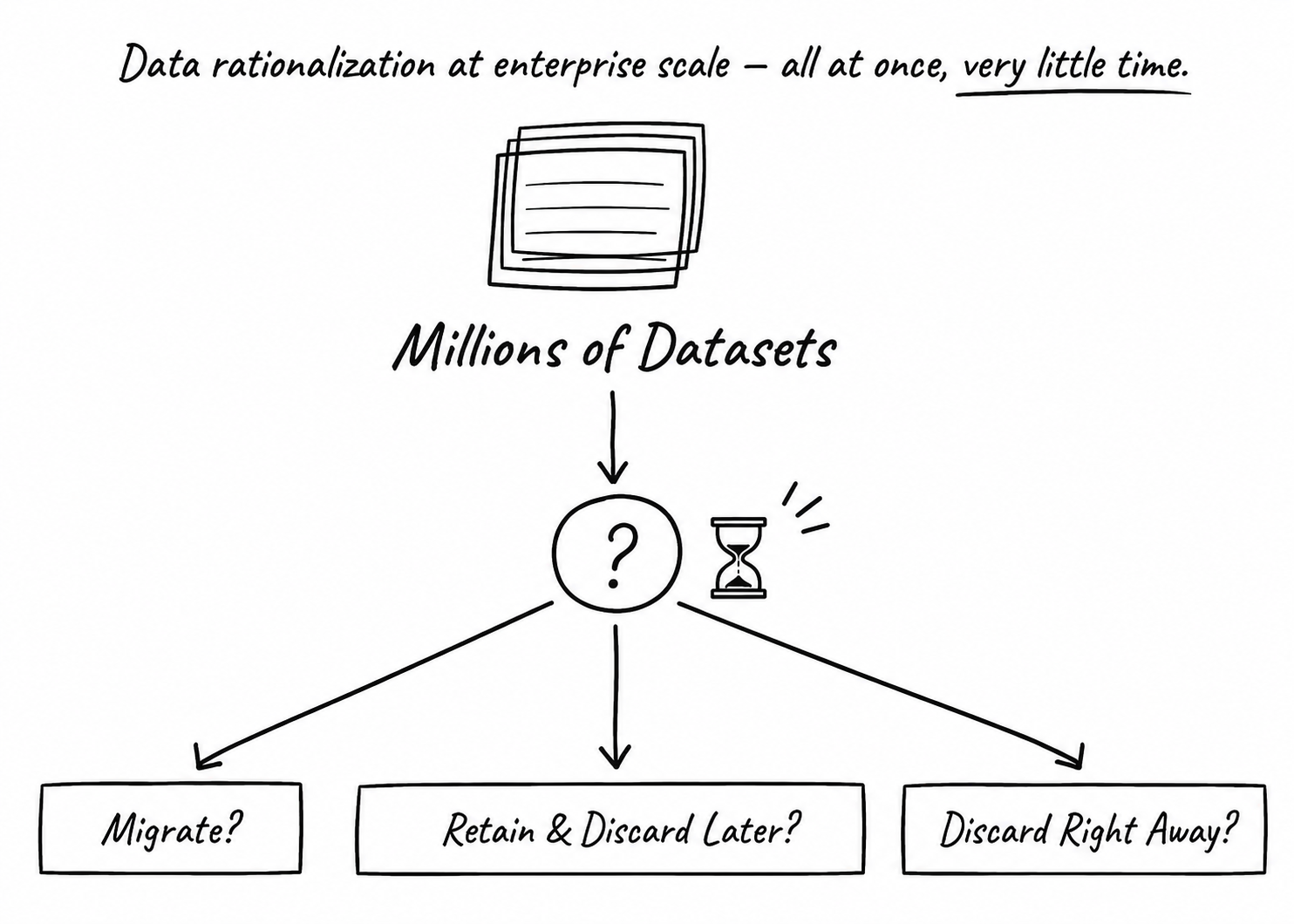
Because every dataset migrated carries a cost. Storage costs. Engineering costs. Governance costs. Operational support costs. Risk management costs. Every unnecessary dataset that survives a merger becomes part of the acquiring company's future burden.
Technical debt, I've learned over the years, always insists on traveling first class.
P.S. Mergers of this scale highlight the value of bringing mature governance standards together. When done well, the acquiring organization's discipline raises the governance maturity of the combined ecosystem rather than diminishing it.
The Questions Nobody Could Answer
As we started evaluating the data ecosystem, we discovered something uncomfortable. For a surprising number of datasets, we couldn't confidently answer even the most basic questions.
Who owns this dataset?
Who uses it?
What business process depends on it?
Is it actively consumed, or has it simply been sitting untouched for years?
Does it contain regulated information?
Would anybody notice if it disappeared tomorrow?
These weren't academic questions. They were multi-million-dollar questions.
Every week we delayed rationalization, infrastructure costs continued to accumulate. Every dataset migrated unnecessarily increased future operational overhead. Every dataset retired incorrectly created the potential for business disruption, regulatory exposure, or broken downstream processes.
The challenge wasn't simply moving data. The challenge was making thousands of business decisions at scale.
And business decisions require context. Unfortunately, context was in short supply.
Why the Most Important Data Was the Least Documented
One lesson seems to repeat itself in every large organization I've worked with: the datasets everyone worries about are rarely the datasets with the best documentation.
The reason is almost mechanical. Data governance controls had always existed, but over the past decade the policies and standards behind them matured considerably, capturing far richer metadata than earlier generations ever required. And like most controls, they fire on change: a schema change, an ETL logic change, a new pipeline trips a gate that forces metadata up to current standard. Newer datasets passed through those gates again and again, so they accumulated clean, conformant metadata.
The most entrenched datasets did the opposite. Created years ago, wired into operational processes, and left untouched precisely because they worked, they never changed, and so never tripped a gate. The assets the business depended on most quietly slipped under the radar of every control designed to document them.
It wasn't that nobody noticed. The question did come up: should we go back and document the critical legacy datasets anyway? The answer was almost always no. These datasets were on borrowed time, soon to be replaced by high-grade, well-governed future-state data products. Why invest in documenting assets that were on their way out? The economics seemed obvious at the time.
The data was there. The documentation never was.
And if you've spent enough time in this industry, you've met one such cryptic dataset. Some version of a table named:
CUSTOMER_PROFILE_V7_FINAL
Nobody remembers who created it. Nobody wants to claim ownership of it. For the Data Engineering team, it's one of thousands of tables to which data gets loaded. They operate the data pipeline, but do not own the dataset.
And absolutely nobody wants to be the person who deletes it. Because somewhere deep down, everyone suspects it might be important.
Following the Footprints
At this point, we realized opinions were not going to solve the problem. Every stakeholder had a view of what mattered. Every business unit had assets they considered critical. Every team had historical reasons why something should be preserved.
What we needed was concrete evidence.
So we began collecting metadata. Lots of it: Physical metadata, Logical metadata, Usage metadata, Ownership metadata. Anything that could help us understand not only what the data was, but whether it actually mattered.
One particular category became incredibly valuable: Usage metadata.
People often tell you what they believe is important. Their behavior tells you what is actually important.
Some datasets that were described as mission critical hadn't been queried in months. Others with minimal documentation were being accessed hundreds of times each week by multiple business teams.
Usage patterns became our equivalent of footprints at a crime scene. They revealed where people had actually been, not where they claimed to have been.
The data, as it turns out, was surprisingly honest.
The Plot Twist Nobody Expected
Over the previous few years, we had worked diligently to build modern, well-governed data products at Company B, exactly the kind of data assets you'd expect to carry forward into a future state. So the assumption felt safe: the legacy datasets would be retired, and our newer datasets would survive. After all, newer and modern data design should win.
Except mergers don't work that way.
The acquiring company had already established a clear future-state architecture, governance framework, operating model, and technology standards. The decision had effectively been made before many of the individual datasets were even evaluated.
The question wasn't whether Company B's data products were good. Many were. The question was whether they aligned with the future state that Company A had already chosen.
Those are entirely different conversations.
As a result, many newer data products were ultimately not prioritized for migration. Instead, attention shifted toward legacy datasets that supported operational processes, risk functions, analytics, and regulatory obligations. Ironically, those legacy assets often carried the weakest metadata and the fewest available subject matter experts (SME).
The Clock Was Working Against Us
Mergers don't just consolidate technology. They consolidate organizations.
As staffing models evolved, experienced employees departed, retiring, changing roles, accepting severance, moving on. The knowledge was walking out the door while the data remained behind.
We had just a few months to evaluate well over a million datasets while simultaneously losing access to many of the people who understood them.
Imagine being handed a library with an incomplete catalog and no veteran librarians, then being told to identify every book worth keeping before the building closes. That was essentially our challenge.
Narrowing the Universe
Eventually, the metadata began telling a story. Ownership patterns emerged. Usage patterns emerged. Business dependencies became visible. Datasets that appeared important were later eliminated. Datasets that initially seemed insignificant suddenly surfaced as critical assets. Usage metadata such as reads, writes, and access patterns became one of the strongest signals for distinguishing belief from reality.
Gradually, the universe became smaller. The migration candidate pool shrank from well over a million datasets to tens of thousands.
It was a remarkable achievement. For a brief moment, we felt like we had solved the problem.
Then we looked at what would be required to properly govern those candidates per Company A's mature and well-established data management policy and standards. And that's when the real problem finally revealed itself.
Each dataset needed dozens of new metadata attributes to be curated: Definitions. Ownership (Data Stewards). Privacy classifications. Risk classifications. Business Criticality. Regulatory Impact.
Then there were the columns. Hundreds of thousands of them.
By the time the calculations were complete, even the most conservative estimate required a level of effort measured in tens of thousands of hours. Those columns would require metadata review, classification, and enrichment. The direct labor cost alone would have reached into seven figures before accounting for program overhead. Ironically, cost wasn't the constraint. Time was.
The compressed merger timeline, unfortunately, remained unchanged.
The Realization
Looking back, this was the moment the entire initiative changed direction.
We had treated the challenge as a migration problem. It wasn't.
We had treated it as a governance problem. It wasn't that either.
What we were really facing was a knowledge problem.
The organization possessed the data. The organization possessed the technology. The organization possessed governance frameworks, policies, standards, and controls. What it lacked was a scalable way to convert institutional knowledge into usable metadata before that knowledge disappeared.
For the first time in my career, I found myself asking a different question. We had spent decades teaching people how to govern data.
What if we could teach an AI Agent to help govern the Data?
That question would eventually lead us to the Data Governance Agent. The Agent is designed to do all the mechanical work, tirelessly, with the data stewards as the human-in-the-loop.
People often complain that AI is doing the creative work while humans are left with the repetitive tasks. Metadata curation is one of those tasks. Most data stewards would rather focus on governing data than documenting it.
And this knowledge problem isn't unique to mergers. Every large organization must contend with the loss of institutional knowledge. As AI adoption accelerates and workforces evolve, that challenge is becoming harder to ignore.
In Part 2, I'll walk through the discovery that manual metadata curation at that scale was never going to work, and how that realization pushed us toward AI-assisted governance.